




 +7 (499) 577-04-84
+7 (499) 577-04-84 pc@huananzhi.ru
pc@huananzhi.ru






До внедрения всё выглядит просто: поставить больше ядер, больше памяти, быстрый SSD — и база должна летать. После запуска выясняется другое: 32 ядра простаивают, NVMe показывает красивые цифры только в рекламном тесте, а пользователи жалуются на задержки при записи документов и отчётах. Разберём без магии, как IT-руководителю выбирать сервер под PostgreSQL: где нужны частота CPU и быстрый fsync, сколько RAM закладывать под кэш, какие SSD смотреть для базы, а где популярные советы только сбивают с толку.
Миф №1: PostgreSQL всегда нужен процессор с максимальным числом ядер
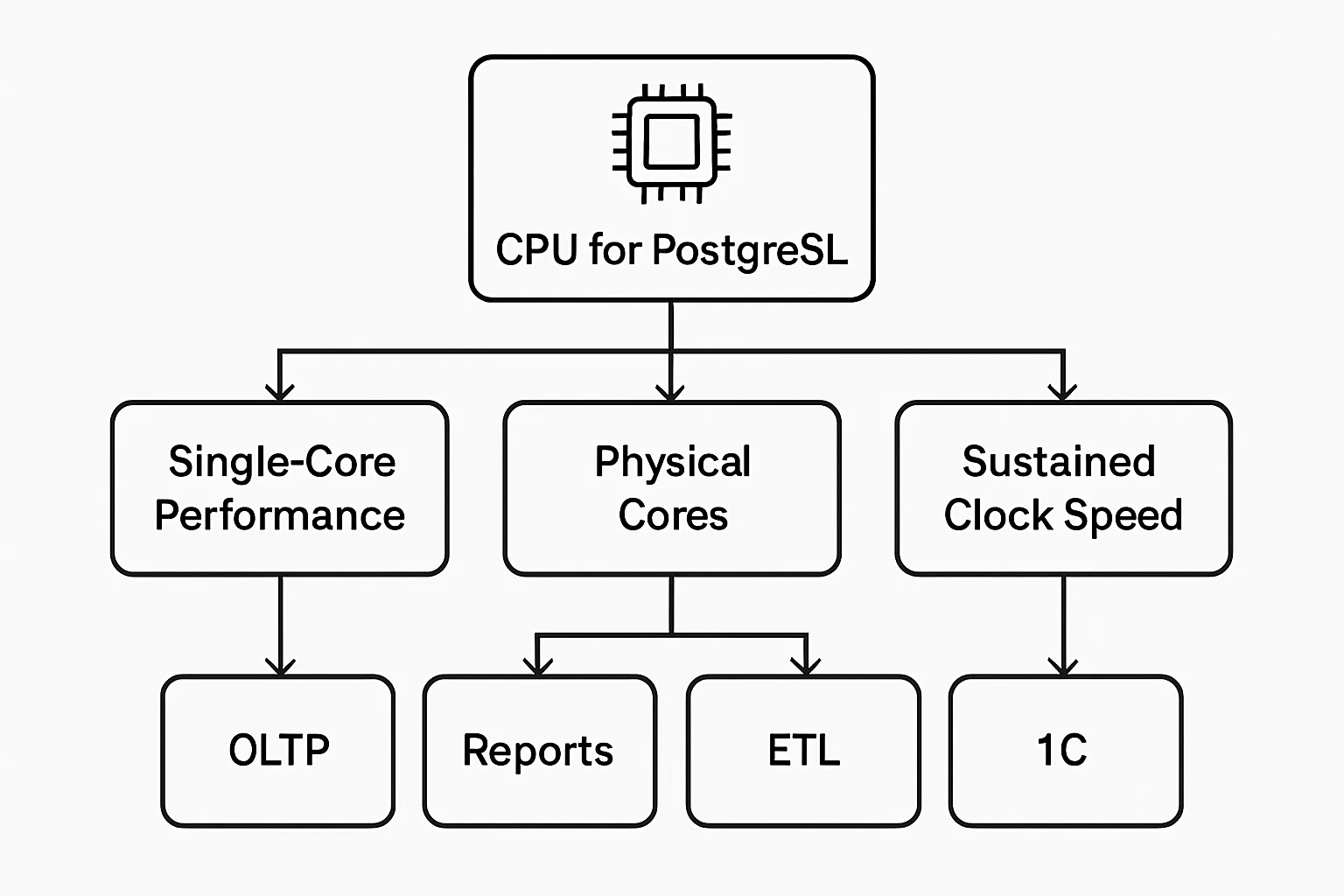
У PostgreSQL многопроцессная архитектура: каждое подключение обычно обслуживается отдельным процессом, фоновые задачи живут отдельно, параллельные запросы тоже могут использовать несколько worker-процессов. Поэтому ядра важны. Но вывод «чем больше ядер, тем лучше» слишком грубый.
Для базы чаще критичны три параметра CPU:
- производительность на ядро — особенно для коротких OLTP-запросов, 1С, CRM, ERP и внутренних сервисов;
- количество физических ядер — чтобы выдерживать конкурентные подключения, фоновые задачи, autovacuum, отчёты, резервное копирование;
- частота под длительной нагрузкой, а не только максимальный boost в спецификации.
Если база обслуживает много коротких транзакций, например учётную систему или сервер для 1С на PostgreSQL, слабое ядро будет ощущаться быстрее, чем нехватка десятков дополнительных потоков. Один тяжёлый запрос, блокировка или сортировка могут занимать конкретный процесс, и «лишние» ядра не всегда спасают задержку пользователя.
Практический ориентир:
- до 20–30 активных пользователей приложения: часто достаточно 6–12 физических ядер при хорошей частоте;
- 30–100 пользователей, отчёты, фоновые задания: обычно смотрят в сторону 12–24 ядер;
- аналитика, большие параллельные запросы, ETL: число ядер становится важнее, но вместе с памятью и дисковой подсистемой;
- смешанный сценарий «PostgreSQL + приложение + резервное копирование на той же машине» требует отдельного запаса.
Важно различать активных пользователей и просто количество учётных записей. 100 сотрудников в компании не означают 100 одновременных тяжёлых запросов к базе. И наоборот: 20 пользователей с плотными отчётами могут загрузить сервер сильнее, чем 80 пользователей, которые вносят короткие операции.
Что не стоит делать: выбирать CPU только по числу потоков в таблице. Для PostgreSQL лучше смотреть на баланс: достаточное число физических ядер, высокая производительность на ядро, нормальное охлаждение и серверная платформа с ECC-памятью.
Миф №2: RAM нужна только «чтобы база поместилась целиком»
Хорошо, когда рабочий набор данных помещается в память. Но PostgreSQL использует RAM не как простую коробку для всей базы. Часть памяти забирает сам PostgreSQL, часть — операционная система под файловый кэш, часть — подключения, сортировки, хэш-операции, обслуживание индексов и фоновые процессы.
Упрощённо память делится так:
- shared_buffers — внутренний буфер PostgreSQL;
- page cache ОС — кэш файлов базы на уровне операционной системы;
- work_mem — память на операции сортировки и хэширования, причём не на сервер целиком, а на операцию;
- maintenance_work_mem — обслуживание индексов, vacuum, restore;
- память под подключения, приложение, мониторинг, агенты резервного копирования.
Распространённая ошибка — поднять work_mem «с запасом» и забыть, что он может умножаться на число активных операций. Например, если поставить work_mem = 256 МБ, а одновременно несколько десятков запросов выполняют сортировки и hash join, фактический расход может стать неожиданно большим. Это не значит, что work_mem должен быть маленьким всегда. Это значит, что его нельзя считать как фиксированный один раз выделенный объём.
Ориентиры по RAM зависят от размера активного набора данных, а не только от полного размера базы:
- база 100 ГБ, но активно используются последние 10–20 ГБ — можно жить с меньшим объёмом RAM, если диски быстрые и запросы нормальные;
- база 500 ГБ, отчёты регулярно читают большие диапазоны — память и диски работают вместе, одного большого кэша может не хватить;
- много подключений без пулера — часть RAM уходит на процессы, а не на полезный кэш;
- 1С и похожие системы часто чувствительны к задержкам, поэтому экономить на RAM до постоянного чтения с диска не стоит.
Практический подход для IT-руководителя: сначала оценить не весь объём базы, а горячие данные. Это таблицы и индексы, к которым обращаются постоянно: текущий период, активные документы, справочники, очереди, последние события. Если горячий набор 40–80 ГБ, сервер с 32 ГБ RAM будет постоянно обращаться к накопителям. Если 64–128 ГБ — уже появляется пространство для кэша, но конкретный эффект зависит от запросов и индексов.
ECC-память для PostgreSQL желательна не как маркетинговая галочка, а как защита от тихих ошибок в данных. База данных — не тот слой, где хочется узнавать о сбое памяти по повреждённому индексу или странному поведению приложения.
Миф №3: любой NVMe одинаково быстрый для базы
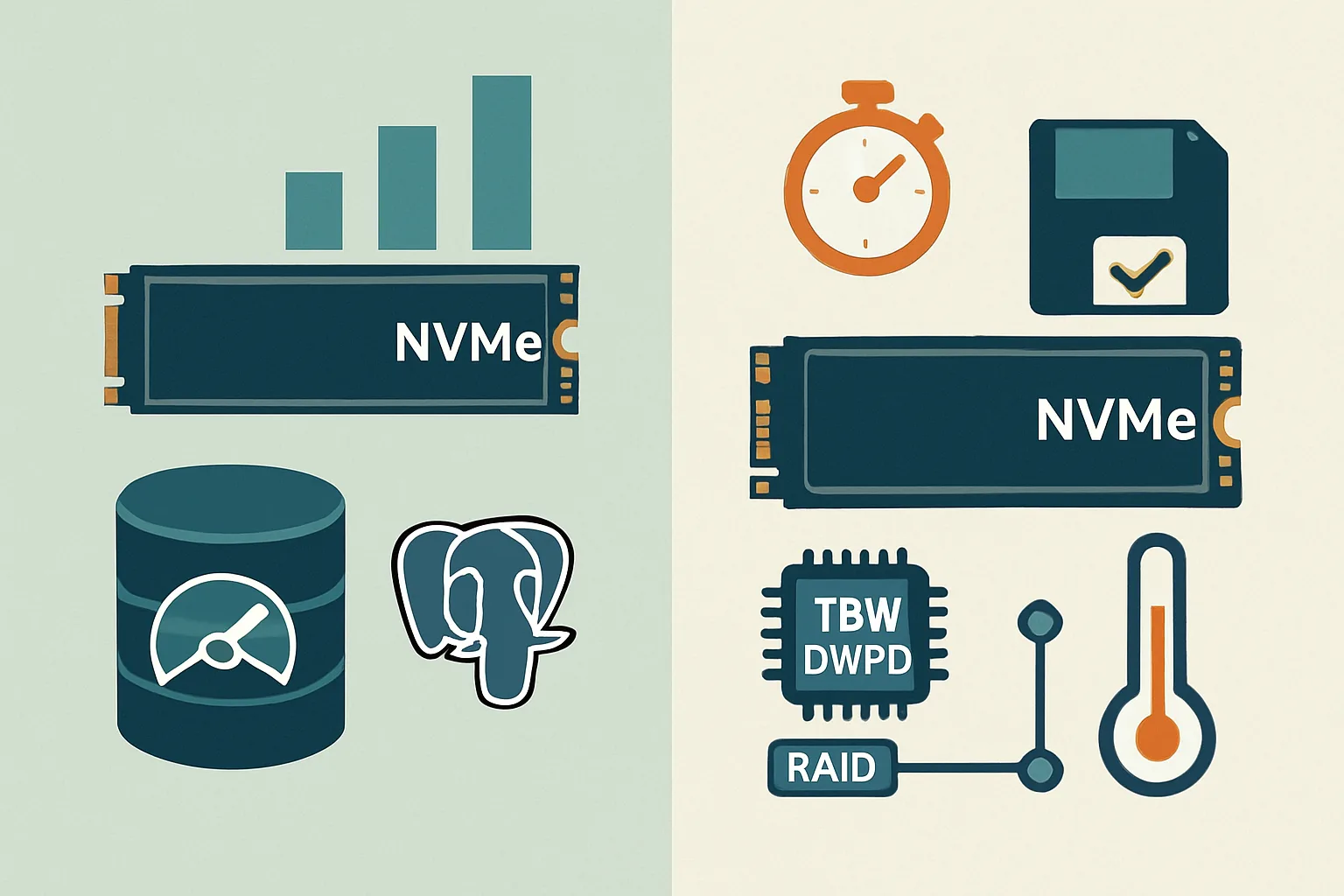
NVMe важен, но для PostgreSQL не все характеристики одинаково полезны. В карточке накопителя могут быть впечатляющие гигабайты в секунду на последовательном чтении, а база при этом будет страдать от задержек записи WAL и случайного I/O.
Для PostgreSQL смотрим не только на «до 7000 МБ/с», а на:
- задержку и стабильность fsync — важна для подтверждения транзакций;
- случайное чтение и запись небольшими блоками;
- наличие PLP — защита от потери питания у серверных SSD;
- ресурс записи TBW/DWPD — особенно при активных обновлениях, индексах, WAL и vacuum;
- поведение под длительной нагрузкой — чтобы накопитель не уходил в резкое снижение скорости после заполнения SLC-кэша;
- температурный режим — NVMe без нормального обдува может троттлить.
Для базы данных потребительский NVMe может быть быстрым в коротком тесте, но неприятным в длительной эксплуатации: нестабильные задержки, нагрев, ограниченный ресурс записи, отсутствие PLP. Это не означает, что он никогда не подходит. Для тестовой базы, dev-среды или небольшого внутреннего сервиса — возможно. Для продуктивной базы с важными транзакциями лучше смотреть на серверные или хотя бы более выносливые модели.
Разносить ли WAL и данные по разным SSD? Ответ зависит от нагрузки. Если база небольшая, а накопитель качественный, один быстрый массив может быть нормальным вариантом. Если запись интенсивная, много транзакций, есть отчёты и фоновые операции, отдельный накопитель или отдельная группа под WAL может снизить конкуренцию за I/O. Но это не универсальное правило: плохой отдельный SSD под WAL может ухудшить ситуацию.
RAID тоже не отменяет здравый смысл. Для PostgreSQL часто рассматривают зеркало или RAID10 на быстрых SSD/NVMe: отказоустойчивость плюс предсказуемая задержка. RAID5/6 на базе с активной записью обычно требует осторожности: штраф на запись и поведение контроллера могут стать узким местом.
Если подбираете накопители, имеет смысл смотреть не только объём, но и класс устройства. В каталоге HUANANZHI Russia есть раздел с SSD и NVMe-накопителями для серверов и рабочих станций — его удобно использовать как отправную точку, но финальный выбор всё равно лучше привязывать к профилю записи, объёму базы и требованиям к отказоустойчивости.
Пример расчёта: база 300 ГБ, 60 пользователей, отчёты днём
Возьмём типовой сценарий: компания использует внутреннюю учётную систему или 1С-подобную нагрузку на PostgreSQL. В базе около 300 ГБ. Активно работают 60 пользователей, пиковая одновременная активность — 20–30 человек. Днём запускаются отчёты, ночью — резервное копирование и обслуживание.
Что важно оценить до выбора железа:
- размер горячих таблиц и индексов: условно 60–100 ГБ;
- доля записи: документы, статусы, очереди, обмены;
- тяжёлые отчёты: читают текущий месяц или несколько лет;
- окно резервного копирования;
- допустимое время простоя при отказе диска;
- будет ли PostgreSQL жить на физическом сервере или внутри VM.
Один из разумных ориентиров для такой задачи:
- CPU: 12–16 физических ядер с хорошей производительностью на ядро;
- RAM: 128 ГБ, если горячий набор действительно в районе 60–100 ГБ и есть отчёты;
- диски: минимум зеркало из качественных NVMe/SSD под данные, отдельное место под бэкапы не на том же массиве;
- сеть: 10 GbE полезна, если есть быстрые бэкапы, репликация, большой обмен с приложением или NAS;
- питание: ИБП обязателен, особенно если накопители без полноценной защиты от потери питания.
Почему не «сразу 32 ядра и 512 ГБ RAM»? Потому что без профиля нагрузки это может оказаться слабым вложением. Если задержка сидит в WAL fsync или в плохих индексах, дополнительные ядра не дадут ожидаемого результата. Если отчёты делают последовательное чтение сотен гигабайт, память поможет лишь частично. Если приложение открывает слишком много подключений, иногда сначала нужен пулер соединений, а не новый процессор.
Почему не «8 ядер и 32 ГБ, потом посмотрим»? Потому что при базе 300 ГБ и активных отчётах сервер может сразу уйти в постоянное чтение с накопителей, а обслуживание базы начнёт конкурировать с пользователями. Масштабирование потом возможно, но миграция продуктивной базы почти всегда сложнее, чем небольшой запас на старте.
Правильный расчёт не сводится к одной таблице. Но он должен отвечать на простой вопрос: какие операции в пике одновременно происходят на сервере — транзакции пользователей, отчёты, autovacuum, бэкап, репликация, антивирус, мониторинг, приложение?
PostgreSQL на физическом сервере или в виртуализации: где граница разумного
PostgreSQL можно запускать в виртуальной машине. Многие компании так и делают: удобнее управлять резервными копиями VM, миграциями, снапшотами, ресурсами и обслуживанием. Hyper-V и Proxmox VE — рабочие платформы для таких сценариев, при условии что хранилище и настройки сделаны аккуратно.
Но есть нюанс: база данных плохо переносит непредсказуемые задержки дисков. Если сервер виртуализации одновременно обслуживает PostgreSQL, файловые сервисы, RDP, тестовые VM и ещё пару систем, проблемы могут выглядеть как «PostgreSQL тормозит», хотя виноват общий storage.
Для VM с PostgreSQL особенно важны:
- выделенный запас CPU без постоянного overcommit;
- понятная политика по RAM, без агрессивного ballooning для продуктивной базы;
- быстрый и устойчивый datastore;
- отсутствие тяжёлых снапшотов в рабочее время;
- мониторинг latency на уровне гипервизора и гостевой ОС;
- резервное копирование, согласованное с PostgreSQL, а не только копия диска VM.
Когда физический сервер предпочтительнее:
- база критична для работы компании;
- высокая запись и чувствительность к задержкам;
- нужен предсказуемый I/O;
- нет зрелой команды по сопровождению виртуализации;
- хост виртуализации уже загружен другими сервисами.
Когда виртуализация уместна:
- нагрузка умеренная;
- есть нормальное shared storage или быстрые локальные NVMe;
- ресурсы VM не конкурируют с шумными соседями;
- команда умеет мониторить не только CPU/RAM, но и дисковую задержку;
- нужно быстрое восстановление и удобное обслуживание.
Здесь важно не путать роли. Сервер виртуализации может быть хорошей базой для PostgreSQL, если его проектировали с учётом I/O базы. Но если PostgreSQL просто «подселили» на уже загруженный хост, стабильности ждать сложно.
Отдельная история — GPU сервер. Для обычного PostgreSQL видеокарты не нужны. GPU имеет смысл рядом с базой, если сервер выполняет локальные ИИ-задачи, обработку изображений, ML-инференс или аналитику через отдельные инструменты. Но покупать GPU ради ускорения типовой транзакционной PostgreSQL-базы — почти всегда неверная постановка задачи.
Короткий чек-лист перед покупкой сервера под PostgreSQL
Перед тем как утверждать конфигурацию, полезно пройтись по вопросам. Они быстро показывают, где нужен запас, а где ожидания завышены.
1. Нагрузка понятна?
- сколько активных пользователей в пике;
- какие операции самые тяжёлые;
- есть ли отчёты в рабочее время;
- какой рост базы за месяц;
- сколько записей и обновлений, а не только чтения.
2. CPU выбран по сценарию, а не по красивому числу потоков?
- для OLTP важна производительность на ядро;
- для отчётов и ETL важны ядра и память;
- для смешанной нагрузки нужен баланс;
- частота под нагрузкой важнее короткого boost.
3. RAM рассчитана с учётом кэша и подключений?
- оценён горячий набор данных;
- не завышен work_mem без понимания параллельности;
- есть запас под autovacuum, бэкапы, мониторинг;
- используется ECC-память для продуктивной базы.
4. SSD/NVMe подходят именно для базы?
- понятны TBW/DWPD;
- проверено поведение под длительной записью;
- есть охлаждение накопителей;
- продуманы RAID1/RAID10 или другая схема отказоустойчивости;
- бэкапы лежат не только на том же массиве.
5. Виртуализация не добавляет случайные задержки?
- нет чрезмерного overcommit CPU;
- RAM не отбирается у VM в пике;
- снапшоты не ломают рабочее окно;
- latency дисков смотрят на уровне гипервизора;
- резервное копирование учитывает консистентность PostgreSQL.
6. Есть план обслуживания?
- мониторинг CPU, RAM, IOPS, latency, WAL, autovacuum;
- регулярные тесты восстановления из бэкапа;
- контроль разрастания таблиц и индексов;
- понятное окно обновлений;
- документация по конфигурации.
Самые частые ошибки: брать максимум ядер при слабом дисковом слое, ставить дешёвый NVMe без учёта ресурса записи, экономить на RAM для базы с активными индексами, держать бэкап на том же массиве, переносить PostgreSQL в VM без контроля задержек, рассчитывать сервер по размеру базы без анализа горячих данных.
Стабильный PostgreSQL — это не один «самый мощный» компонент. Это связка CPU, RAM, NVMe, питания, охлаждения, резервного копирования и понятной эксплуатации. Если один слой выбран случайно, он и станет ограничителем.


