




 +7 (499) 577-04-84
+7 (499) 577-04-84 pc@huananzhi.ru
pc@huananzhi.ru






Типичная ситуация из практики: заказчик просит «сервер помощнее под виртуалки», называет 10–15 будущих ВМ и сразу смотрит в сторону двухпроцессорной машины с максимумом ядер. Через полчаса выясняется, что половина ВМ почти простаивает, узкое место будет в дисках, а резервное копирование упрётся в один гигабитный порт. Сервер виртуализации надо собирать не от красивой спецификации, а от профиля нагрузки: сколько ВМ, какие роли, какой рост, как хранятся данные и как быстро это всё нужно восстановить после сбоя.
Шаг 1. Сначала описываем виртуальные машины, а не выбираем процессор
Хороший подбор начинается с инвентарной таблицы. Не с модели CPU, не с объёма SSD, а с перечня сервисов, которые реально будут жить на хосте.
Минимальный набор вопросов:
- сколько ВМ будет на старте и через 12–24 месяца;
- какие роли у ВМ: AD/DNS, файловый сервер, SQL, сервер для 1С, терминальные службы, мониторинг, телефония, Linux-сервисы, тестовые среды;
- сколько пользователей работает одновременно;
- какие ВМ критичны, а какие можно остановить на обслуживание;
- нужен ли live migration или достаточно одного автономного хоста;
- какой гипервизор планируется: Hyper-V, Proxmox VE, VMware, другой стек;
- где будут резервные копии и сколько времени допустимо восстанавливать сервис.
Документация Microsoft по Hyper-V и документация Proxmox VE сходятся в главном: виртуализация — это не только CPU. Важны память, подсистема хранения, сеть, драйверы, контроллеры, совместимость и архитектура резервирования.
Для инженера полезно делить ВМ на три группы:
1. Фоновые сервисы — контроллер домена, DNS, DHCP, мониторинг, небольшие Linux-службы. Обычно требуют немного CPU, но должны быть стабильны. 2. Рабочая нагрузка пользователей — RDS/терминальные сервера, сервер приложений, сервер для 1С, базы данных. Здесь важны задержки, частота ядра, RAM и быстрый storage. 3. Тяжёлые или нестандартные задачи — видеоаналитика, локальные ИИ-модели, CAD/рендер, GPU passthrough. Для них может понадобиться уже не просто сервер виртуализации, а GPU сервер или отдельная рабочая станция под конкретное ПО.
Если этот список не составлен, почти любой выбор железа будет угадыванием. Иногда угадывают удачно, но чаще покупают лишние ядра и экономят на дисках или сети — а потом получают медленные снимки, долгие бэкапы и жалобы пользователей.
Шаг 2. CPU: считать не только ядра, но и характер нагрузки
В виртуализации легко попасть в ловушку: увидеть много ВМ и решить, что нужен максимум физических ядер. На практике важны три параметра: число ядер, частота на ядро и запас по планировщику гипервизора.
Что учитывать при выборе CPU:
- vCPU не равен физическому ядру. ВМ можно назначить 2–4 vCPU, но это не значит, что все они постоянно загружены. Для офисных сервисов часто допустима умеренная переподписка, но для SQL, 1С и терминальных нагрузок её надо ограничивать.
- Частота важна для 1С, SQL и старых приложений. Некоторые нагрузки хуже масштабируются по многим ядрам и лучше реагируют на высокую производительность одного ядра.
- Два сокета нужны не всегда. Двухпроцессорная платформа даёт больше линий PCIe, слотов памяти и суммарных ядер, но добавляет тепла, требований к питанию и нюансов NUMA. Если ВМ немного, один более быстрый CPU иногда практичнее.
- NUMA стоит учитывать заранее. Для крупных ВМ, которым выделяют много vCPU и RAM, важно не пересекать NUMA-границы без необходимости. Иначе можно получить задержки, которые не видны в красивой строке спецификации.
Ориентир по vCPU:pCPU зависит от профиля. Для слабонагруженных офисных ВМ иногда начинают с 2:1 или выше, но для баз данных, терминальных серверов и нагруженной 1С лучше закладывать осторожнее и проверять по мониторингу. Универсальной пропорции нет.
Где обычно переплачивают:
- берут CPU с большим числом ядер, когда нагрузка упирается в диски;
- ставят много vCPU каждой ВМ «на всякий случай», ухудшая планирование;
- выбирают серверный CPU без учёта лицензирования ПО, где стоимость может зависеть от ядер;
- покупают двухсокетную платформу ради «запаса», хотя рост можно закрыть вторым хостом через год.
Правильный подход: сначала определить критичные ВМ, затем выделить им гарантированный ресурс, а уже потом смотреть, сколько остаётся на вспомогательные сервисы.
Шаг 3. Память: запас нужен, но overcommit не должен быть планом выживания
Виртуализация любит RAM. Если CPU можно иногда переподписать, то с памятью всё жёстче: когда начинается активное вытеснение, ballooning или swap, пользователи быстро это чувствуют.
Что закладывать:
- объём RAM под каждую ВМ по рабочему профилю, а не по минимальным требованиям ОС;
- запас под гипервизор, кэш файловой системы и служебные процессы;
- резерв на рост баз, пользователей и новых ролей;
- возможность добавить модули без полной замены комплекта.
Для серверов виртуализации обычно разумно использовать ECC RDIMM/LRDIMM, если платформа это поддерживает. Дело не в магии, а в снижении риска ошибок памяти на машине, где одновременно работают десятки сервисов. Особенно если хост включён 24/7 и обслуживает бизнес-критичные ВМ.
Важно не только «сколько гигабайт», но и как заполнены каналы памяти. Если процессор поддерживает несколько каналов, лучше не ставить один большой модуль и оставлять пропускную способность на столе. Но и забивать все слоты мелкими модулями без плана роста — тоже не лучший вариант.
Практический ориентир: если после расчёта получается 160–180 ГБ рабочей потребности, не стоит собирать сервер ровно на 192 ГБ без понимания роста. При появлении ещё пары ВМ запас исчезнет. Но и ставить 1 ТБ «на всякий случай» не всегда оправдано: лучше проверить, действительно ли рост будет по RAM, а не по дискам или лицензиям.
Отдельный случай — VDI и терминальные фермы. Там память надо считать по одновременным пользователям и профилю приложений. Браузеры, офисные пакеты, тонкие клиенты, тяжёлые бухгалтерские базы и CAD ведут себя по-разному. Одна и та же конфигурация может быть нормальной для RDS с офисными задачами и слабой для графической нагрузки.
Шаг 4. Диски: скорость ВМ часто решается не объёмом, а задержками и схемой хранения
Подсистема хранения — частая причина разочарования после покупки сервера. В спецификации написано «несколько терабайт SSD», а на практике бэкап тормозит рабочие ВМ, база отвечает рывками, а snapshot превращается в источник проблем.
Разделяйте роли дисков:
- диски под гипервизор — отдельный небольшой RAID1 или зеркальная пара;
- datastore для ВМ — быстрые SSD/NVMe с понятной схемой отказоустойчивости;
- хранилище бэкапов — отдельные диски, NAS или внешний репозиторий, не на том же массиве, где крутятся рабочие ВМ;
- архивы и холодные данные — можно хранить дешевле, если они не влияют на рабочие задержки.
SATA SSD подойдут для умеренной офисной нагрузки, но NVMe полезны там, где много случайных операций: базы, терминальные серверы, активные файловые сервисы, несколько ВМ с параллельным I/O. SAS/HDD остаются уместны для больших объёмов и архивов, но ставить на них активные ВМ без кэша и понимания нагрузки рискованно.
RAID тоже не выбирают по привычке. RAID1 прост и понятен для пары дисков. RAID10 часто практичен для ВМ, если нужны предсказуемые задержки и нормальное восстановление. RAID5/6 на SSD или HDD может быть уместен в отдельных сценариях, но надо учитывать штраф на запись, время rebuild и поведение контроллера. В ZFS важны RAM, правильные vdev, питание и дисциплина с sync-записью; это не «бесплатный RAID получше», а отдельная архитектура.
Мини-расчёт по I/O: допустим, есть 8 активных ВМ. Две из них — SQL/1С и терминальный сервер, остальные — инфраструктурные. Если каждая фоновая ВМ даёт немного операций, а база и RDS периодически создают пики, то общий средний IOPS может выглядеть скромно. Но пользователи жалуются не на среднее, а на задержку в пике. Поэтому один большой SATA SSD без зеркала и без запаса по записи может оказаться хуже, чем меньший, но грамотно собранный NVMe RAID1/10.
Хранилище бэкапов лучше отделять физически. Облачные сервисы уровня корпоративного диска, например тарифы Yandex 360 Disk для бизнеса, могут быть частью схемы для копий и обмена файлами, но их не стоит воспринимать как прямую замену локальному datastore для ВМ. Это разные сценарии по задержкам, доступности и управлению восстановлением.
Шаг 5. Сеть: один гигабитный порт быстро становится бутылочным горлом
Сеть в сервере виртуализации часто вспоминают в конце: «порт же есть». Но через этот порт идут пользователи, администрирование, бэкапы, миграции, доступ к NAS, репликация и иногда видеопотоки.
Практичный минимум для небольшого хоста:
- отдельный порт или VLAN для управления;
- отдельный канал для пользовательского трафика ВМ;
- отдельный канал для бэкапов и хранения, если есть NAS/SAN;
- IPMI/BMC для удалённого доступа к серверу вне ОС;
- запас по слотам PCIe под 10GbE/25GbE адаптер.
1GbE ещё жив в небольших офисах, но для бэкапов виртуальных машин он часто становится ограничением. Простая оценка: передать 1 ТБ по гигабиту в идеальных условиях — это не «пара минут», а часы, и реальные накладные расходы увеличат время. Если окно резервного копирования короткое, 10GbE может оказаться не роскошью, а нормальным инженерным решением.
Для кластера виртуализации сеть важнее ещё сильнее. Live migration, репликация, Ceph/ZFS replication, доступ к общему хранилищу — всё это требует не только скорости, но и предсказуемости. Лучше сразу продумать VLAN, MTU, LACP или независимые интерфейсы, чем потом выяснить, что миграция ВМ забивает тот же канал, по которому работают пользователи.
Не стоит забывать про коммутатор. Если сервер получил 10GbE, но подключён к офисному коммутатору с одним аплинком и без нормального управления, часть преимуществ потеряется. Сервер, сеть и хранилище надо считать одной системой.
Пример подбора: один хост для интегратора на 12–15 ВМ
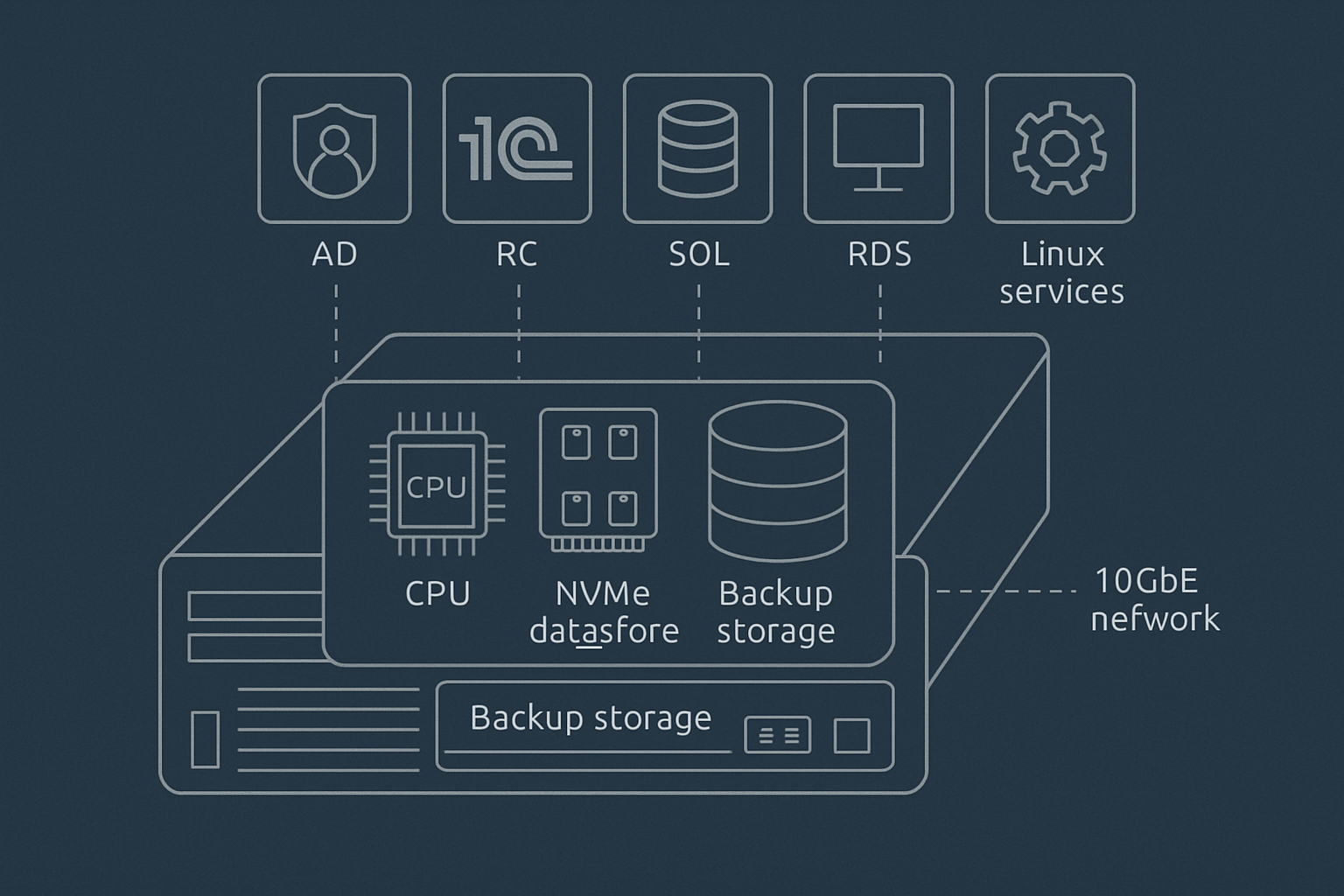
Возьмём типовой сценарий: интегратор собирает сервер виртуализации для клиента на 40–60 пользователей. На старте планируются:
- 2 ВМ инфраструктуры: AD/DNS, мониторинг;
- 1 файловый сервер умеренного объёма;
- 1 сервер для 1С и отдельная ВМ под СУБД;
- 2 терминальных сервера;
- 2–3 Linux-сервиса;
- тестовая ВМ;
- резерв под ещё 3–4 машины в течение года.
Логика подбора может быть такой.
CPU. Не гнаться за максимальным числом ядер. Нужен серверный процессор или пара процессоров с достаточным количеством физических ядер и хорошей частотой. Для 1С/СУБД и RDS важно не раздать всем ВМ по 8 vCPU, а выделить разумные лимиты и следить за ready time/очередями планировщика.
RAM. Считаем роли: инфраструктура 8–16 ГБ суммарно, файловый сервер по задаче, СУБД и 1С заметно больше, RDS по числу одновременных пользователей. Если грубый расчёт даёт 180–220 ГБ, практичнее смотреть в сторону 256–384 ГБ с возможностью роста, а не собирать ровно впритык.
Диски. Отдельная зеркальная пара под систему гипервизора, быстрый datastore под активные ВМ, отдельный репозиторий бэкапов. Для СУБД и терминальных серверов лучше заложить NVMe или хорошо собранный SSD-массив. Объём считать не только по текущим VHDX/QCOW2, но и по росту баз, snapshots, временным файлам и резервным копиям.
Сеть. Минимум несколько интерфейсов, желательно 10GbE для бэкапов/хранилища, если объём ВМ измеряется терабайтами и есть ограниченное окно обслуживания. Управление — отдельно, IPMI — обязательно для нормальной поддержки.
GPU. Если заказчик просит «на будущее под ИИ», надо уточнять задачу. Для обычной виртуализации GPU не нужен. Для passthrough видеокарт в ВМ, локального inference, видеоаналитики или графических рабочих мест уже нужен другой проект: GPU сервер, подходящая плата, питание, охлаждение, линии PCIe и совместимость гипервизора. Иногда дешевле и надёжнее вынести такую нагрузку в отдельную рабочую станцию или специализированный узел.
Это не готовая универсальная спецификация. Это порядок мышления: сначала роли и узкие места, потом железо.
Где такой сервер не подходит и какие ошибки встречаются чаще всего
Один мощный сервер виртуализации не всегда правильный ответ. Иногда лучше два менее нагруженных хоста, иногда — отдельный NAS, иногда — часть сервисов в облаке, иногда — физический сервер под конкретную базу.
Когда стоит пересмотреть идею одного хоста:
- требуется высокая доступность без длительного простоя;
- есть жёсткие RTO/RPO по восстановлению;
- нагрузка быстро растёт и плохо прогнозируется;
- много тяжёлых баз данных с активной записью;
- планируется VDI или GPU passthrough для большого числа пользователей;
- нет нормального помещения, питания, охлаждения и резервного копирования.
Частые ошибки при сборке:
1. Покупают ядра вместо системы. CPU мощный, но диски медленные, сеть 1GbE, бэкапы лежат на том же массиве. 2. Назначают ВМ слишком много vCPU. Кажется, что так быстрее, а на деле растёт конкуренция за планировщик. 3. Экономят на RAM и надеются на overcommit. Для тестового стенда допустимо, для рабочих сервисов — риск. 4. Не отделяют бэкапы от рабочих данных. Сбой массива или шифровальщик может затронуть всё сразу. 5. Не проверяют совместимость. Контроллеры, сетевые карты, NVMe, passthrough, драйверы и гипервизор должны дружить до закупки. 6. Не считают лицензии. Иногда лишние ядра обходятся дороже самого железа из-за лицензирования ОС, СУБД или прикладного ПО. 7. Не оставляют план роста. Свободные слоты RAM, PCIe, корзины под диски и запас питания важны не меньше текущей конфигурации.
Короткий чек-лист перед финальной спецификацией:
- [ ] есть список ВМ с ролями, vCPU, RAM, дисками и критичностью;
- [ ] выделены ВМ с высокой задержкочувствительностью: SQL, 1С, RDS, телефония;
- [ ] выбран гипервизор и проверена совместимость железа;
- [ ] рассчитан datastore отдельно от репозитория бэкапов;
- [ ] понятна схема RAID/ZFS и процедура восстановления после отказа диска;
- [ ] сеть разделена хотя бы логически: управление, пользователи, бэкапы/хранилище;
- [ ] есть IPMI/BMC и доступ к серверу при падении ОС;
- [ ] заложен рост на 12–24 месяца без полной пересборки;
- [ ] проверено питание, охлаждение, шум и место установки;
- [ ] понятно, что не будет виртуализировано и почему.
Если после чек-листа конфигурация стала скромнее — это нормально. Если стала дороже — тоже возможно, но уже по причине конкретных требований, а не из-за абстрактного «надо помощнее».
Ещё по теме на huananzhi.ru
Читайте также
- X99 на Xeon в 2026 году: рабочая серверная платформа или ловушка дешёвого бюджета
- 5 ошибок при выборе серверной материнской платы: где ломается конфигурация под 1С, GPU, NAS и VDI
- ECC или обычная память в сервере: как понять, где коррекция ошибок обязательна, а где это лишняя сложность


